
Contact-Sheet Index
DOJ FTA / EFTA00004577
EpsteinGate
Search by person, EFTA ID, PDF filename, House Oversight ID, file type, or keyword across more than one million DOJ Epstein documents. Find co-mentions where two people appear in the same records. Every document is ranked for significance, tagged with names and entities, and connected to the investigations worth reviewing first.
Direct file lookup: EFTA ID, PDF filename, or House Oversight ID
Search People in the Files
Search tracked individuals across the DOJ Epstein and House Oversight files. Results include file counts from power mention tagging.
DOJ FTA / EFTA00004577

DOJ FTA / EFTA00005538

DOJ FTA / EFTA00004577

DOJ FTA / VOL00003

DOJ FTA / EFTA00005536

DOJ FTA / EFTA00005538

DOJ FTA / EFTA00004577

DOJ FTA / EFTA00005538

DOJ FTA / EFTA00005538

DOJ FTA / EFTA00005567

DOJ FTA / EFTA00005538

DOJ FTA / VOL00003
What This Project Does
There are millions of pages in the Epstein releases: EFTA PDFs, FBI interviews, 302 memos, financial records, flight logs, court material, and media files. If you already know the file, name, or file type you want, this search is built to take you there quickly.
We read every document in the corpus, extract names, entities, and connections, write plain-language explanations of what each record contains, and assign an investigative significance rating. You're searching a curated research layer, not just a file dump.
We use the same system to publish original investigations. When something significant surfaces from search traffic, our newsroom, or reader submissions, we verify it against the files and publish with full source citations. Readers can also submit leads for follow-up.
What You Can Search
If you already know the file, person, or reference you want, start here. These are the fastest paths into the corpus.
How It Works
The scale of these releases is designed to overwhelm. We built a system that refuses to be overwhelmed.
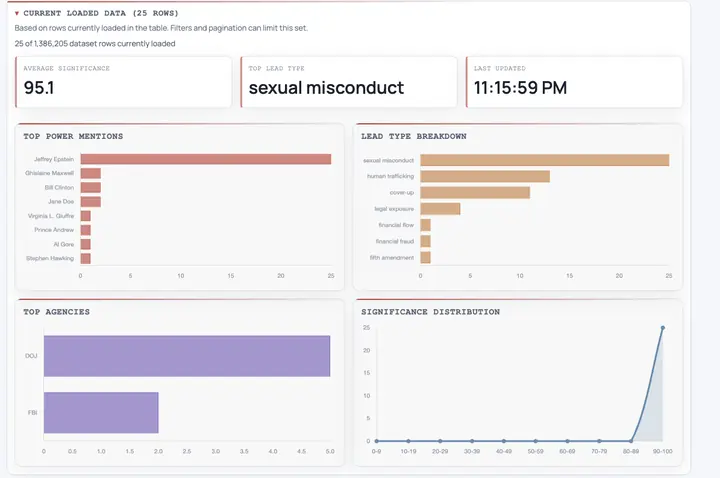
Millions of pages scanned for text, layout, redactions, and handwritten notes. Every document is ranked for investigative significance and tagged with names, dates, file references, and connections.
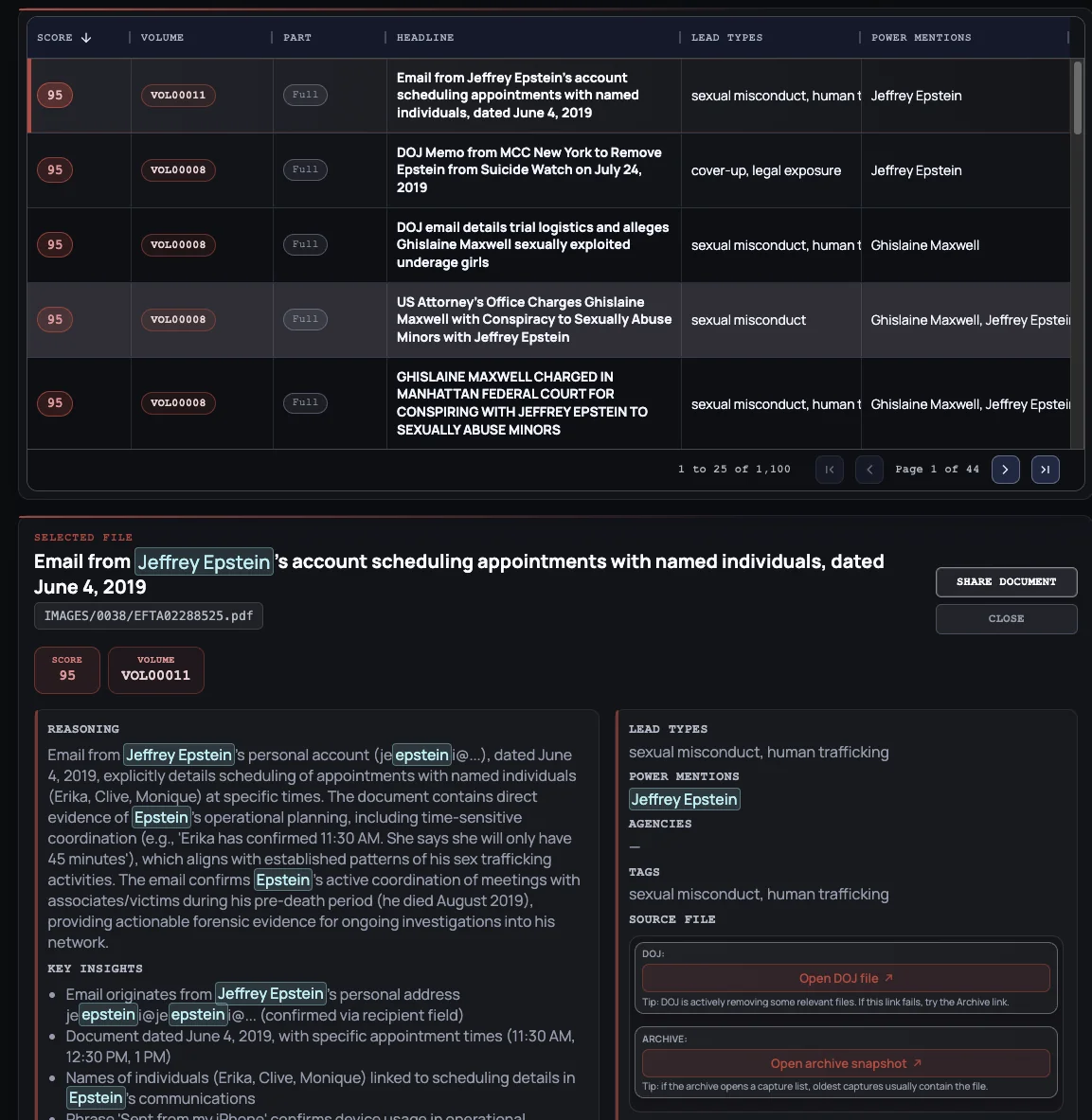
The corpus, ranked by investigative significance, powers our public file search. Look up EFTA IDs, PDF filenames, names, aliases, file types, and lead types. Search co-mentions to find where two people appear in the same records.
When something significant surfaces from search traffic, our newsroom, or outside reporters, we dig in. We verify against the source files, follow the paper trail, and publish with full source citations.
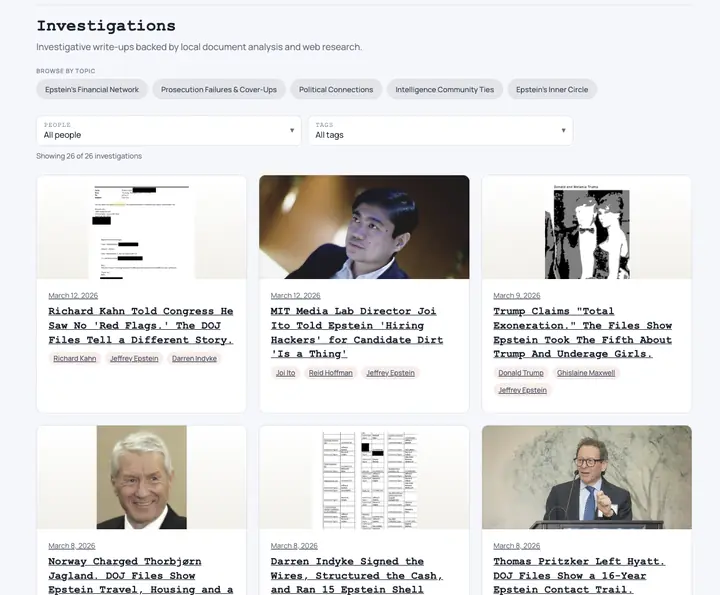
Feature Investigations
Loading the latest investigations...
FAQ
Enter the EFTA ID, House Oversight ID, or PDF filename directly into file search. The explorer resolves lookups such as EFTA02858481, HOUSE_OVERSIGHT_013470, or EFTA02858495.pdf and routes you into the matching record.
Use the person search on the homepage or go to the viewer and select names in the power mentions filter. Type a name to see autocomplete suggestions from 400+ tracked individuals. You can also select two people to find co-mentions — every document where both names appear together.
We keep extracted metadata, entities, file-level explanations, and significance ratings so researchers can still understand what a record contains and recover its reference trail even if the source location changes.
Some file trails already connect to published reporting. When we have verified the records and written up the findings, we link those investigations so you can move from raw documents to sourced context.
 Search the File ExplorerLook up EFTA IDs, PDF filenames, names, file types, and documents ranked by significance from one searchable archive.
Search the File ExplorerLook up EFTA IDs, PDF filenames, names, file types, and documents ranked by significance from one searchable archive.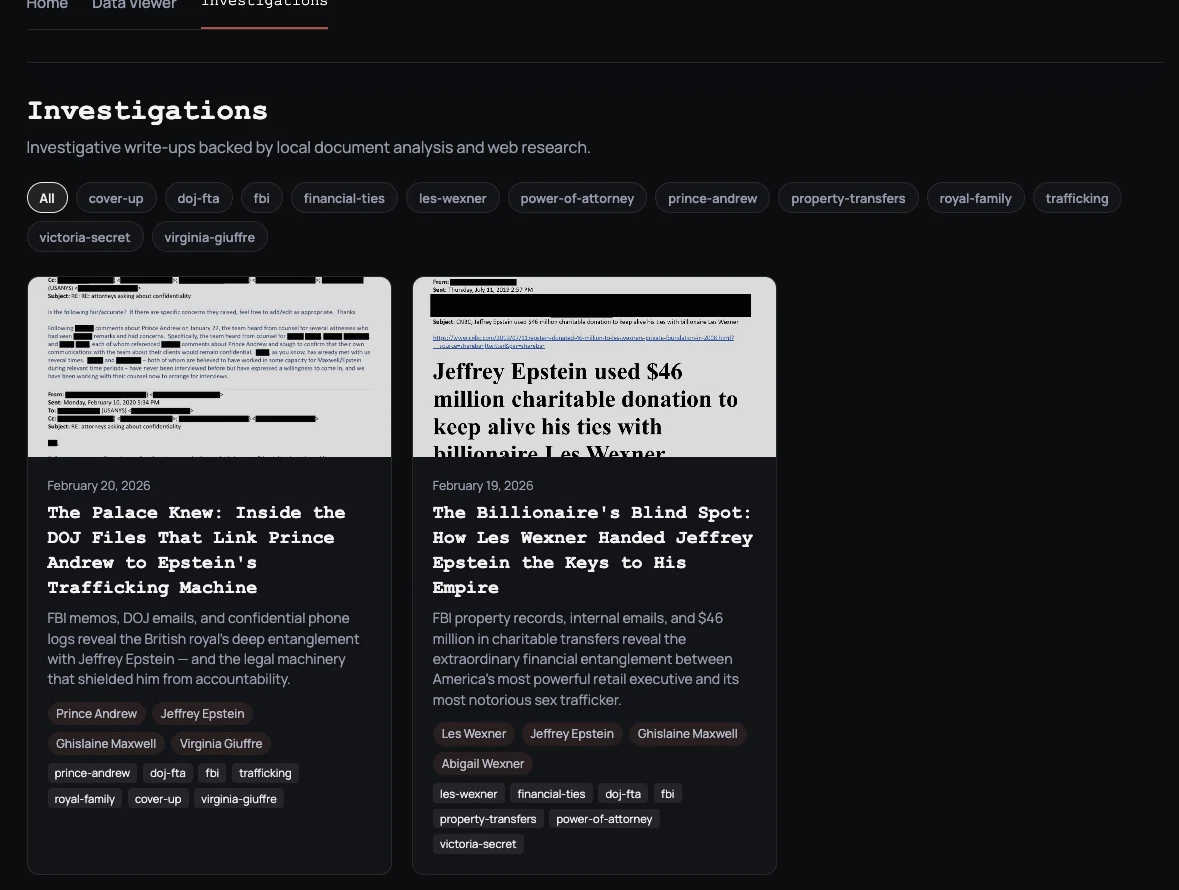
 Read Our InvestigationsOriginal reporting on what surfaced through document analysis, newsroom review, and journalist leads. Every claim sourced. Every document linked.
Read Our InvestigationsOriginal reporting on what surfaced through document analysis, newsroom review, and journalist leads. Every claim sourced. Every document linked.